Double-BenchTeam


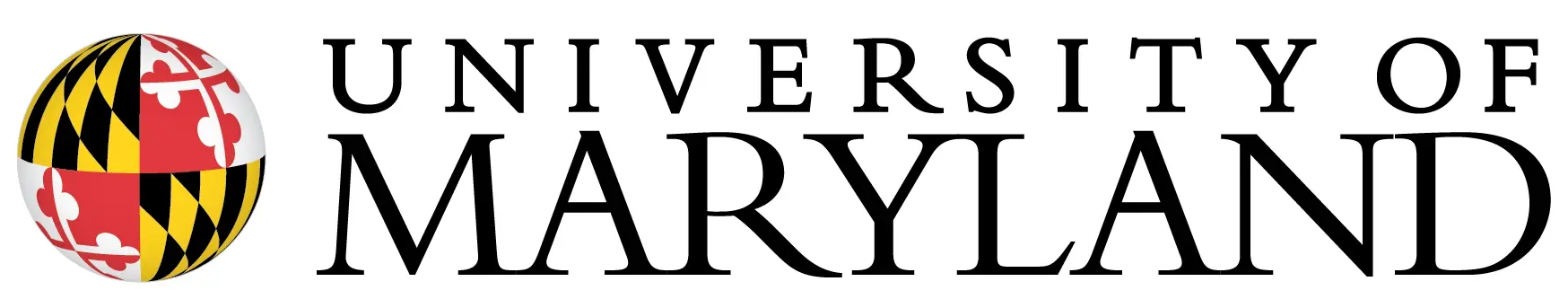
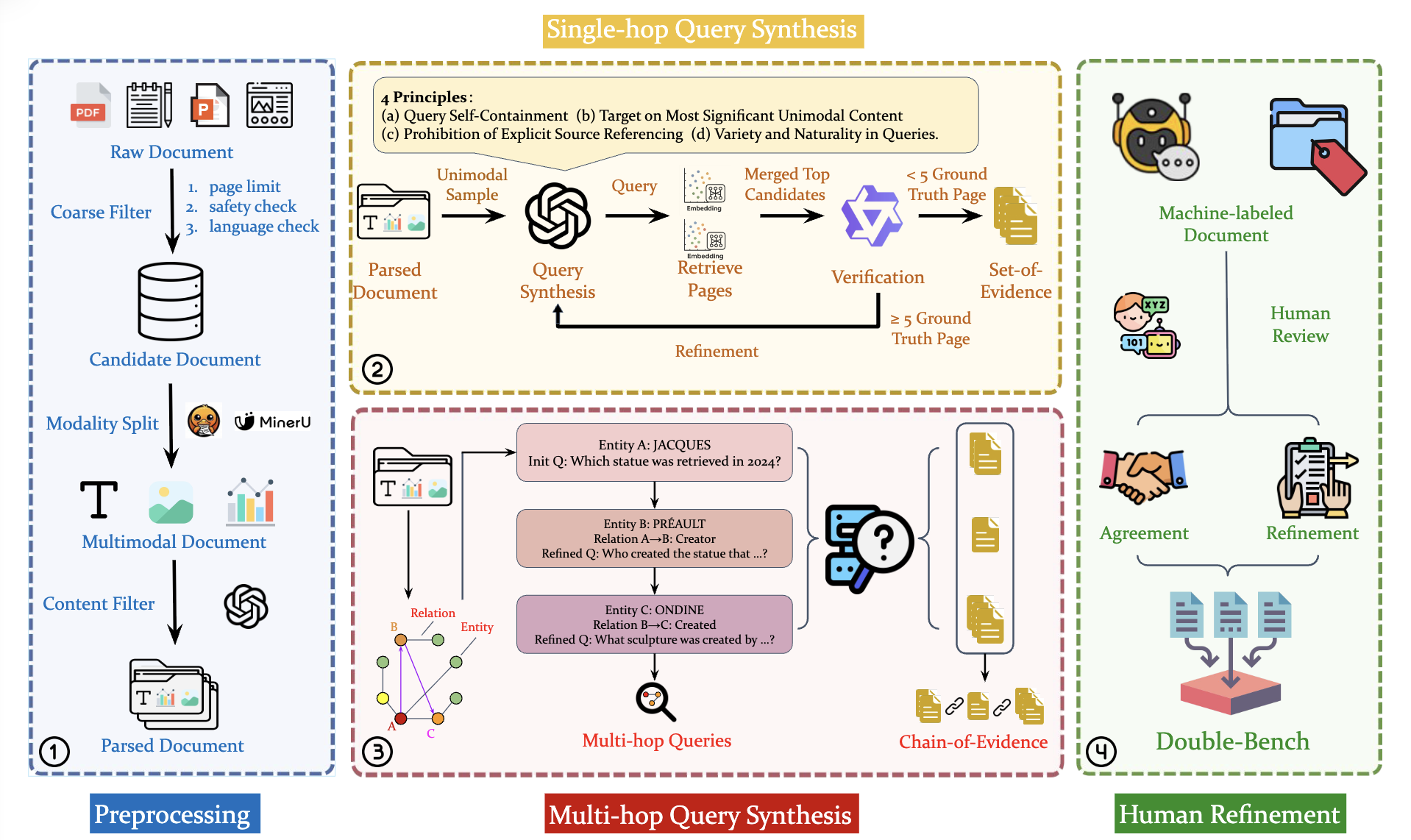
📄 PDFs, 📰 Scanned documents, 🎯 Slides, 🌐 HTML pages; GT: Ground Truth evidence labels, M.H.: Multi-Hop, Lang.: Supported language number, Dyna.: Support dynamic benchmark update
| Benchmarks | Size | Queries | Labels | Evaluation Target | Document | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Doc | Avg. #Pages | Query | Clarity | i.i.d. | M.H. | GT | M.H. Chain | Embed Model | MLLMs | RAG System | Lang. | Dyna. | Type | |
| DocVQA | 6,071 | 1.0 | 50,000 | ✗ | ✗ | ✗ | ✗ | - | ✗ | ✓ | ✗ | 1 | ✗ | 📄 📰 |
| MMLongbench-Doc | 135 | 47.5 | 1,082 | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | 1 | ✗ | 📄 |
| MMDocIR | 6,818 | 65.1 | 73,843 | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | 1 | ✗ | 📄 |
| UDA-QA | 2,965 | 46.3 | 29,590 | ✗ | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | 1 | ✗ | 📄 |
| ViDoRe v1 | 5,000 | 1.0 | 500 | ✓ | ✓ | ✗ | ✓ | - | ✓ | ✗ | ✗ | 2 | ✗ | 📄 📰 |
| ViDoRe v2 | 65 | 48.6 | 913 | ✓ | ✓ | ✗ | ✓ | - | ✓ | ✗ | ✗ | 2 | ✗ | 📄 |
| ViDoSeek | 1,142 | 18.4 | 1,142 | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✓ | 1 | ✗ | 🎯 |
| REAL-MM-RAG | 163 | 49.1 | 4,553 | ✓ | ✓ | ✗ | ✓ | - | ✓ | ✗ | ✗ | 1 | ✗ | 🎯 |
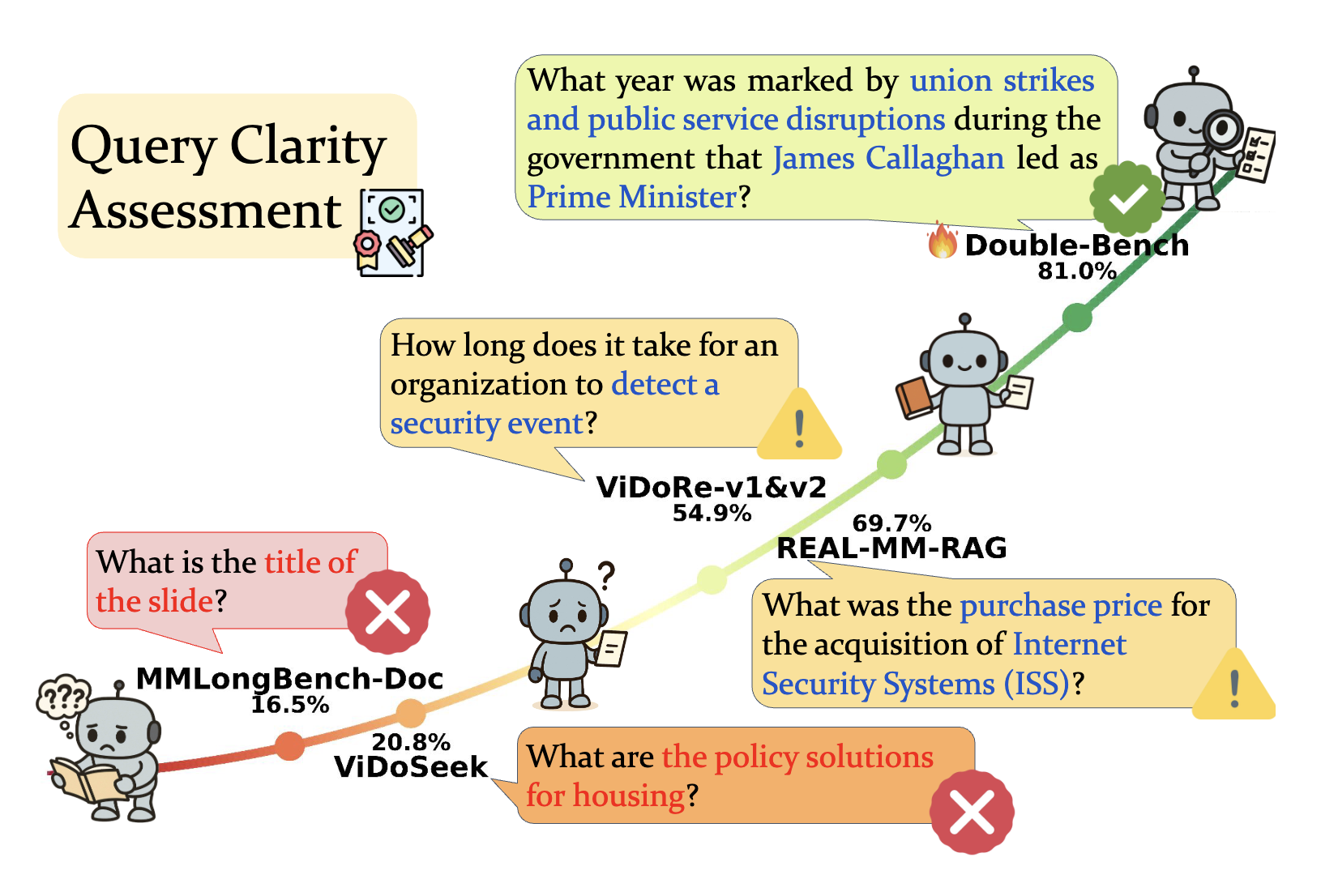
| Double-Bench | 3,276 | 22.3 | 5,168 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 6 | ✓ | 📄 📰 🎯 🌐 |
| Model | Average | Single Hop | 2-Hop | 3-Hop | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| hit@1 | hit@3 | hit@5 | hit@1 | hit@3 | hit@5 | hit@1 | hit@3 | hit@5 | hit@1 | hit@3 | hit@5 | |
| Text Embedding Models | ||||||||||||
| Qwen3-Embedding-4B | 0.489 | 0.699 | 0.776 | 0.726 | 0.852 | 0.886 | 0.314 | 0.598 | 0.663 | 0.235 | 0.531 | 0.668 |
| NV-Embed-v2 | 0.443 | 0.650 | 0.724 | 0.626 | 0.756 | 0.796 | 0.333 | 0.604 | 0.689 | 0.240 | 0.526 | 0.641 |
| gte-Qwen2-7B-instruct | 0.404 | 0.611 | 0.697 | 0.585 | 0.749 | 0.804 | 0.288 | 0.503 | 0.603 | 0.205 | 0.466 | 0.588 |
| bge-m3 | 0.355 | 0.525 | 0.591 | 0.527 | 0.648 | 0.695 | 0.180 | 0.366 | 0.428 | 0.182 | 0.412 | 0.502 |
| Visual & Multimodal Embedding Models | ||||||||||||
| colqwen2.5-3b-multilingual | 0.533 | 0.727 | 0.795 | 0.778 | 0.865 | 0.895 | 0.326 | 0.622 | 0.693 | 0.277 | 0.579 | 0.696 |
| vdr-2b-multi | 0.463 | 0.648 | 0.725 | 0.688 | 0.813 | 0.847 | 0.283 | 0.491 | 0.589 | 0.225 | 0.482 | 0.606 |
| jina-embeddings-v4 | 0.451 | 0.641 | 0.720 | 0.671 | 0.804 | 0.844 | 0.264 | 0.468 | 0.570 | 0.222 | 0.479 | 0.603 |
| gme-Qwen2-VL-7B-Instruct | 0.428 | 0.614 | 0.697 | 0.638 | 0.775 | 0.822 | 0.249 | 0.472 | 0.579 | 0.208 | 0.449 | 0.570 |
| colpali-v1.3 | 0.403 | 0.571 | 0.646 | 0.584 | 0.679 | 0.717 | 0.230 | 0.440 | 0.525 | 0.220 | 0.469 | 0.588 |
Double-Bench provides a clear divergence in the retrieval performance of various embedding models. The model rankings within Double-Bench align well with popular text embedding leaderboards MTEB and document retrieval benchmark ViDoRe v2, demonstrating the robustness of our benchmark.
ColQwen2.5-3B significantly outperforms general multimodal embedding models like jina-embeddings-v4 and GME, achieving a 9% higher average hit rate and demonstrating strong potential in document retrieval. Other multimodal embedding models show limited capability, even underperforming compared to the purely textual embedding model Qwen3-Embedding. We attribute this to recent advancements of text embedding community's sophisticated training techniques, including complex multi-stage training, dedicated hard negative sampling, and large-scale high-quality data synthesis. These techniques are difficult to transfer to visual embedding models due to training costs, limited text-and-image data, and model structural constraints. Although visual embedding models have inherent advantages for visual content retrieval, the semantic complexity of document RAG tasks negates this advantage. The critical influence of both visual observation and textual understanding abilities incentive combined strategies such as interleaved embedding models and advanced multimodal understanding pipelines.
State-of-the-art MLLMs like GPT-4o, Gemini, and Qwen are able to make general responses without context, with 50% to 70% of responses being partially correct. Providing evidence pages to MLLMs substantially boosts accuracy, with 3x to 5x responses being completely correct compared to w.o. RAG setting. This indicates that our benchmark is well-suited for evaluating the retrieval and synthesis components of RAG systems, as it clearly distinguishes context-grounded reasoning from a model's inherent knowledge. Notably, the robust performance of Qwen2.5-VL observed in the upper bound setting, which closely mirrors our benchmark curation pipeline, further suggesting the robustness and effectiveness of our pipeline in identifying correct evidence pages of queries.
Most frameworks strive to design complex information mining pipelines to extract maximum value from retrieved pages, yet tend to pay little attention to the retrieval stage itself. However, our experiments demonstrate strong correlations between retrieval accuracy and answer accuracy. Equipped with a single MLLM pass, Colqwen-gen even partially outperforms MDocAgent on multi-hop queries, despite the latter seamlessly integrating multiple agents to provide final answers. This underscores the critical importance of optimizing the retrieval stage, potentially through finer-grained document preprocessing, exploiting the hierarchical and semantic structure of documents and developing more powerful or integrated embedding models.
To investigate the bottleneck in existing RAG frameworks, we breakdown each reponse of M3DocRAG and MDocAgent to analyze whether the error comes from retrieval or answering, and look into the trade-off between answering accuracy and the ability to identify insufficient information (also known as honesty).
Our experiments reveal a striking divergence in agent behavior. Simpler agents like M3DocRAG adopt a cautious strategy, answering a lower proportion of queries with successfully retrieved context but reliably identifying retrieval failures and refusing to respond. In contrast, more complex agents like MDocAgent and ViDoRAG exhibit significant overconfidence. While they achieve higher accuracy on retrieval hits, they indiscriminately attempt to answer nearly every query, regardless of whether sufficient information was retrieved. This frequently leads to speculative or entirely hallucinated content when evidence pages are missed.
This observation indicates that recent document RAG development has over-emphasized maximizing answer generation at the expense of "epistemic humility", i.e., the crucial skill of knowing what it doesn't know and admitting when an answer cannot be found. Consequently, we argue that future research should pursue more trustworthy RAG frameworks where identifying informational gaps is as valued as accuracy.
We also observe different answering strategy in MLLMs. When directly provided with a multi-hop query, response model tend not to process them hop-by-hop. On the contrary, they first collect signature information---the most distinguishing or identifiable pieces---from the various hops. Following this, models tend to perform a direct inclusion based elimination to arrive the final answer. This mechanism differentiates significantly from our expectation of how models might sequentially solve multi-hop queries. This provides a compelling point of view: merely increasing the number of hops may not increase its difficulty. A case study in Appendix reveals that MLLMs do not process multi-hop queries step-by-step as expected. Instead, they gather key signature information from each hop and use inclusion-based elimination to find the answer. This challenges the assumption that more hops always increase difficulty, suggesting further investigation is needed.
@article{shen2025we,
title={Are We on the Right Way for Assessing Document Retrieval-Augmented Generation?},
author={Shen, Wenxuan and Wang, Mingjia and Wang, Yaochen and Chen, Dongping and Yang, Junjie and Wan, Yao and Lin, Weiwei},
journal={arXiv preprint arXiv:2508.03644},
year={2025}
}